How to Scrape Web Applications in Node.js using Cheerio

Photo by @kmuza on Unsplash
Scraping web applications is one of the most fun subjects for me and maybe for you too. Aside from fun, it is one of the most prime topics in data science.
Many of us may know how to scrape web data using Python or using some online tool. This article, however, will demonstrate how we can scrape data from static websites using Node.js. We will scrape data from this website and show the data in API.
Creating a New Node.js Project
At first, let’s create a new Node.js project. To create a new project, open a new terminal in the working directory, and type the following command:
mkdir my-scraper && cd ./my-scraper
It will create a new folder named my-scraper. To initiate a new Node.js project, type the following command in the terminal in the my-scraper directory.
npm init -y
It will create the file named package.json inside our project directory. Let’s install all the required dependencies as well as express by typing the following command:
npm install express
Set up Basic Code
Now let’s create a file named index.js in the root folder of our project directory. Inside the index.js file, let’s add the basic code below:
const express = require('express') const app = express() const PORT = 8080 app.use(express.json()) app.listen(PORT, () => console.log(`🚀 Server started at ${PORT}.`))
Now, if we enter the following command in the terminal, our server will start:
node .
We can see our server running by going to the URL http://localhost:8080. We can see a web page similar to the following:

Installing Cheerio and Axios
Cheerio is a Node framework, which can be used to scrape web data using Node.js. Let’s install it first. To install Cheerio, you have to put the following command in the terminal:
npm install cheerio
It will install Cheerio in our project.
Let’s also install axios for fetching the HTML code.
npm install axios
Let’s Start Scraping
So far, we have initiated our Node.js project and installed all the required dependencies. Now, we will be starting our journey to scrape data from the website.
First, let’s fetch the HTML code for scraping the data. We will first download the homepage of our target website. Change the index.js code like below:
const axios = require('axios') const cheerio = require('cheerio') const express = require('express') const app = express() const PORT = 8080 app.use(express.json()) app.use('/', async (req, res) => { try { const data = await axios.get('https://webscraper.io/test-sites/e-commerce/allinone') if (data.status !== 200) { return res.status(data.status).send({ message: 'Invalid url' }) } const html = await data.data const $ = cheerio.load(html) return res.status(200).send({ message: 'Everything is okay' }) } catch(err) { console.log(err.message) } }) app.listen(PORT, () => console.log(`🚀 Server started at ${PORT}.`))
Now, let’s fetch all the product lists from the “Top items being scraped right now” section. Hit CTRL+U and observe the HTML code structure. Or you can inspect the code by hitting CTRL+SHIFT+I on your keyboard.
By observing the HTML code, we can see that the cards in the HTML are located in the following step:
div[class="wrapper"] > div[class="container test-site"] > div[class="row"] > div[class="col-md-9"] > div[class="row"] > div[class="col-sm-4 col-lg-4 col-md-4"] > div[class="thumbnail"]
By observing the cards, we can see that each card has an image, a title, a price, a description, a rating, and the total number of reviews. So let’s fetch these records first:
const axios = require('axios') const cheerio = require('cheerio') const express = require('express') const app = express() const PORT = 8080 app.use(express.json()) app.use('/', async (req, res) => { try { const data = await axios.get('https://webscraper.io/test-sites/e-commerce/allinone') if (data.status !== 200) { return res.status(data.status).send({ message: 'Invalid url' }) } const html = await data.data const $ = cheerio.load(html) const result = Array.from($('div[class="wrapper"] > div[class="container test-site"] > div[class="row"] > div[class="col-md-9"] > div[class="row"] > div[class="col-sm-4 col-lg-4 col-md-4"] > div[class="thumbnail"]')).map((element) => ({ imageUrl: 'https://webscraper.io' + $(element).find('img').attr('src').trim(), title: $(element).find('div[class="caption"] > h4 > a').attr('title').trim(), price: $(element).find('div[class="caption"] > h4[class="pull-right price"]').text().trim(), description: $(element).find('div[class="caption"] > p[class="description"]').text().trim(), review_count: parseInt($(element).find('div[class="ratings"] > p[class="pull-right"]').text().trim().split(' ').slice(0, -1).join() || '0'), rating: parseInt($(element).find('div[class="ratings"] > p[data-rating]').attr('data-rating').trim() || '0') })) || [] return res.status(200).send({ result }) } catch(err) { console.log(err.message) } }) app.listen(PORT, () => console.log(`🚀 Server started at ${PORT}.`))
The results are as below:
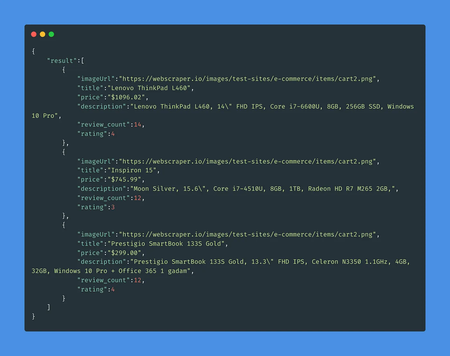
Conclusion
You now have a firm understanding of how we can scrape data from web applications in Node.js. In this article, we have seen how we can use Cheerio to scrape data from static websites.
Scraping web data using Cheerio works with static websites. However, this method might not work for dynamic websites, as in most of the frameworks, the website renders on the client-side.
Again, web scraping is against the terms and conditions of certain web applications. You should check whether you have permission to scrape the information from the website.
Regardless of its limitation, we can scrape the necessary information from other websites and store them in our database easily. Although we can’t fetch data directly from dynamic websites, there is a workaround to fetch data using Cheerio. Maybe I will discuss it in another article.
If you are interested, here is the complete project repository. ludehsar/my-scraper *Tutorial project for Medium. Contribute to ludehsar/my-scraper development by creating an account on GitHub.*github.com
Have a nice day!